【原因と対策】「クロール済み インデックス未登録」「検出 インデックス未登録」Search Console カバレッジ 除外エラーとはなにか?
- 投稿日/更新日
除外エラーが、いま熱い。熱いと言いますか、サイト運用者から「インデックス未登録が増えた」「一向にクロールされない」といった報告を2021年中頃からよく見かけるようになりました。私のサイトもご多分漏れず、インデックス未登録などが複数発生しており、少々困ったことになっています。
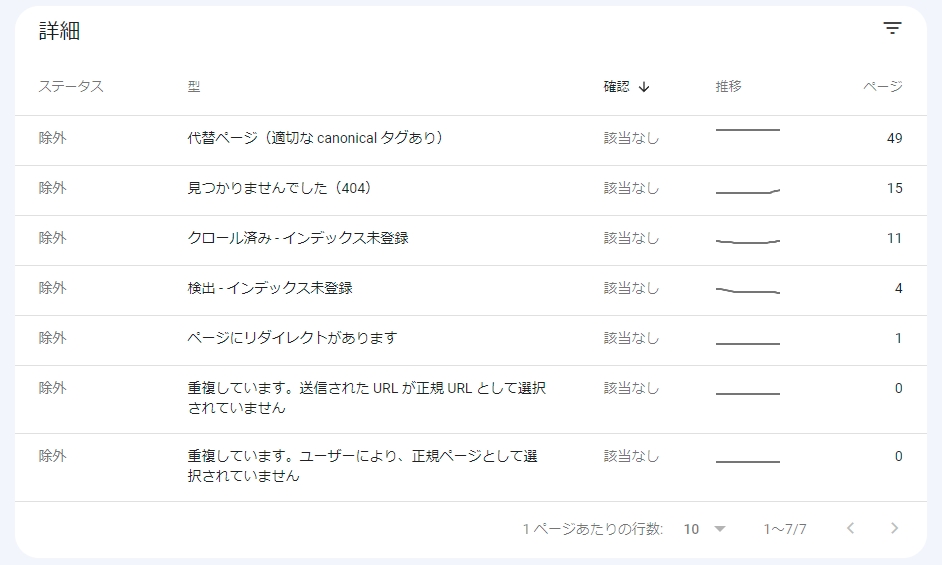
そもそもサーチコンソール カバレッジの除外エラーにはどういった項目があるのでしょうか? Googleのヘルプページにも解説は書かれていますが、いまいち掴みにくい内容もあり、理解できないものもあります。そこで、実サイトの経験を元に解説してみたいと思います。
見つかりませんでした(404)
その名の通り、ページが見つからない場合に検出されます。このエラーはサイトマップには含まれていないものが検出されるそうで、サイト内のリンクを辿って404になっていることが考えられます。リニューアルしたときや大きくサイト構造を変えたときは注意して見ておいたほうがよい項目です。
代替ページ(適切なcanonicalタグあり)

canonicalが設定されているページが検出されます。たとえば、AMPページはcanonicalで通常のページを指定することが仕様で定められているので、AMPを導入しているサイトでは検出されるはずです。上記図の例ですとa_amp.htmlが検出されることになります。除外”エラー”として検出されてますが、通常は何ら問題がないものになります。
ページにリダイレクトがあります
その名の通り、ページにアクセスしたがリダイレクトされたページが検出されます。
noindexタグによって除外されました
クロールしたページのMETAにNOINDEXが指定されている場合に表示されます。NOINDEXにする例としては、サイト内検索の結果画面などはクロールされたくないので、NOINDEXを指定することがあります。もちろん意図してないページがこの項目で検出されていたら確認しておきましょう。
クロール済み インデックス未登録/検出 インデックス未登録
この2つは混在されやすく、そして最も注目されている項目でしょう。YouTubeで定期的に開催されている「Googleポリシーオフィスアワー」の解説を元にすると、下記のような状態になります。
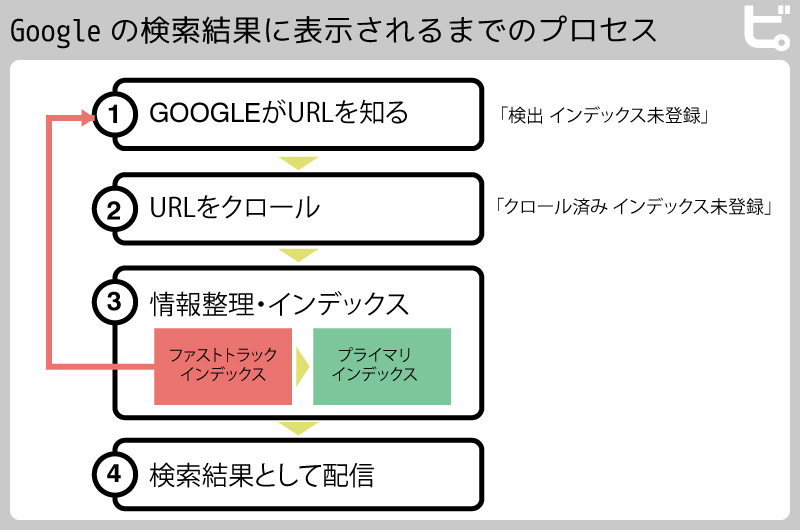
検索結果に表示されるまでのプロセスとして、①Googleが何らかの手段でURLを知る・発見する ②発見したURLをクロールして情報を取得 ③情報を整理・構築する(インデックス) ④検索結果を配信 があるということです。「検出 インデックス未登録」は①が終えた状態、「クロール済み インデックス未登録」は②が終えた状態であることになります。②の場合はインデックスに進む場合もありますが、進まないこともあります。
ここから先のステップに進まないのは様々な要因があるようで一概にはいえないそうです。クロールのエラーが発生していないかとか、HTMLの構成に問題はないか、そもそもサイトマップで送信しているかなど。同オフィスアワーでは、「ページが検索結果に出ないのは削除リクエストされているから」といった利用者の間違い・手違いの事例もありました。
③インデックスまで進んでいるのに、再びインデックスがない状態や①に戻ることがあります。Googleのインデックスには2種類あり、一時的にINDEXするファストトラックインデックス(ファーストではありません、fastです)、恒久的なプリイマリインデックスがあるとの説明が過去にされていますが、この一時的なファストインデックスから何らかの理由でドロップアウトがあるそうです。しかし最近はこのファストインデックスの名前を聞きませんね。
この現象についてはGoogleは一貫して「高品質なコンテンツ」「ページの重要性」と言っており、原因としては「Googleとしてインデックスする価値がない」と判断されています。正直、「Googleがうちのコンテンツの価値の何がわかっとんねん!」と言いたくなりますよね。私も何度暴言を吐いたことか。
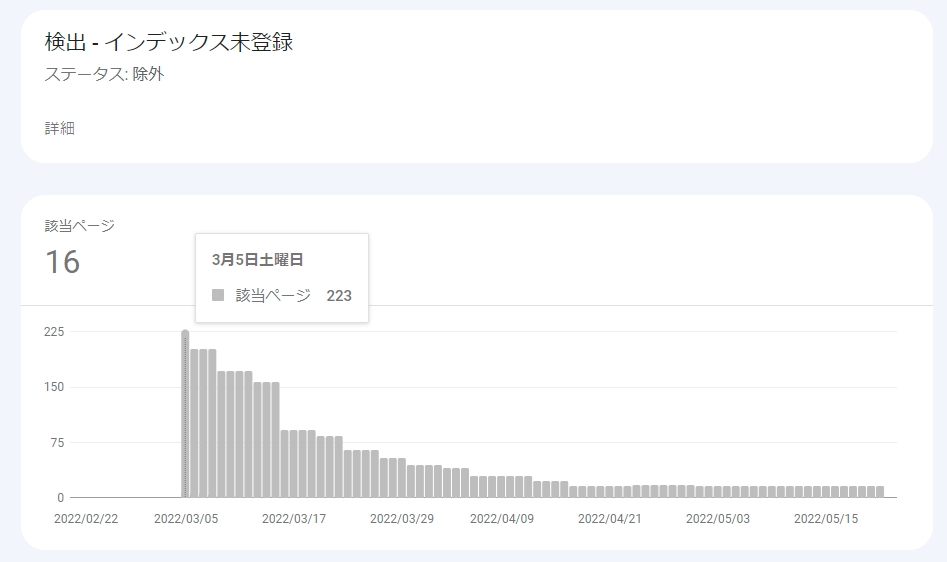
とあるサイトの運用データ実例が上記のグラフです。一時期は「検出 インデックス未登録」が200以上ありましたが、いろいろ対策したところ減ることに成功しました。あまり細かくはお伝えできませんが、解決となるヒントは「サイト内リンクの整理」「被リンク」「テキストの増加」です。それでもしぶとく未登録のままのものがあり困ってます。
重複しています。ユーザーにより、正規ページとして選択されていません
日本語でOKと言いたくなるエラー内容ですが、サイトの中に同じようなURLがいっぱいあるけど何?どれが正しいの?というエラーです。これはサイト内検索やプログラムで表示制御させているものなどが検出されます。https://***/search.cgi?id=a と https://***/search.cgi?id=b のようなものは重複と判断されているようですね。この場合はcanonicalを指定することになります。
重複しています。送信された URL が正規 URL として選択されていません
こちらも上記、重複と同じような内容です。canonicalを指定することで回避できるでしょう。
他にもいくつかの項目がありますが、実例としては以上となります。除外エラーはクロールされていないことにばかり注目されているような気がしますが、そもそもはサイトの健康状態を表す検出だと思います。定期的にウォッチをして、サイトが健全な状態にあるように努めておきたいですね。
備忘録として残しておきます。